
TL;DR
- spike.land treats A/B testing as a reliability system, not just a marketing tactic.
- App variants can be assigned consistently, measured, compared, and promoted only after strict evidence thresholds are met.
- The current decision engine is Bayesian, deterministic, and auditable: 48h minimum runtime, 500 impressions per variant, 95%+ winner probability.
- AI helps generate alternatives and explain failures, but it does not get to “vibe” a winner into production.
Most A/B Testing Is Too Shallow
Most teams use experiments to answer small questions.
Should the button be blue? Should the headline be shorter? Does pricing card A beat pricing card B?
That is fine, but it is not the most interesting use of experiments.
The more valuable question is:
Which variant is less broken?
Once you start asking that, A/B testing stops being a growth-only tool and starts becoming a quality system.
The Two-Part System
spike.land has two related pieces here.
The first is the app-store-facing workflow: deployments, variants, visitor assignment, impression tracking, error tracking, and winner declaration.
The second is the general experiments engine: hash-based assignment, event tracking, Bayesian evaluation, and anomaly monitoring.
That combination lets us do something very practical:
- ship multiple versions
- watch what users actually hit
- measure errors and outcomes
- promote the better version only when the data justifies it
Why AI Belongs In The Loop
The useful role for AI is not “decide the winner.”
The useful role is:
- generate a cleaner variant
- propose a fallback path
- cluster error patterns into likely bug themes
- explain why a losing variant probably failed
That is where AI is strong: ideation, synthesis, diagnosis.
But when it comes to shipping, the platform uses explicit rules.
The Shipping Rules
The current experiment engine is not subtle about its thresholds.
Before a winner can graduate automatically, the experiment must satisfy:
- at least 48 hours of runtime
- at least 500 impressions per variant
- a winning probability above 95%
- at least 10% lift over control unless control itself wins
That is the right balance. We let AI help us explore, but we do not let it hallucinate certainty.
Bayesian Instead Of Wishful
I like Bayesian evaluation here because it matches the real decision:
How likely is it that this variant is actually better?
That is a more useful production question than pretending a dashboard with some percentage lifts and a green checkmark is enough.
The engine samples the posterior for each variant, compares them repeatedly, and measures which one wins most often. That gives us a probability, not just a story.
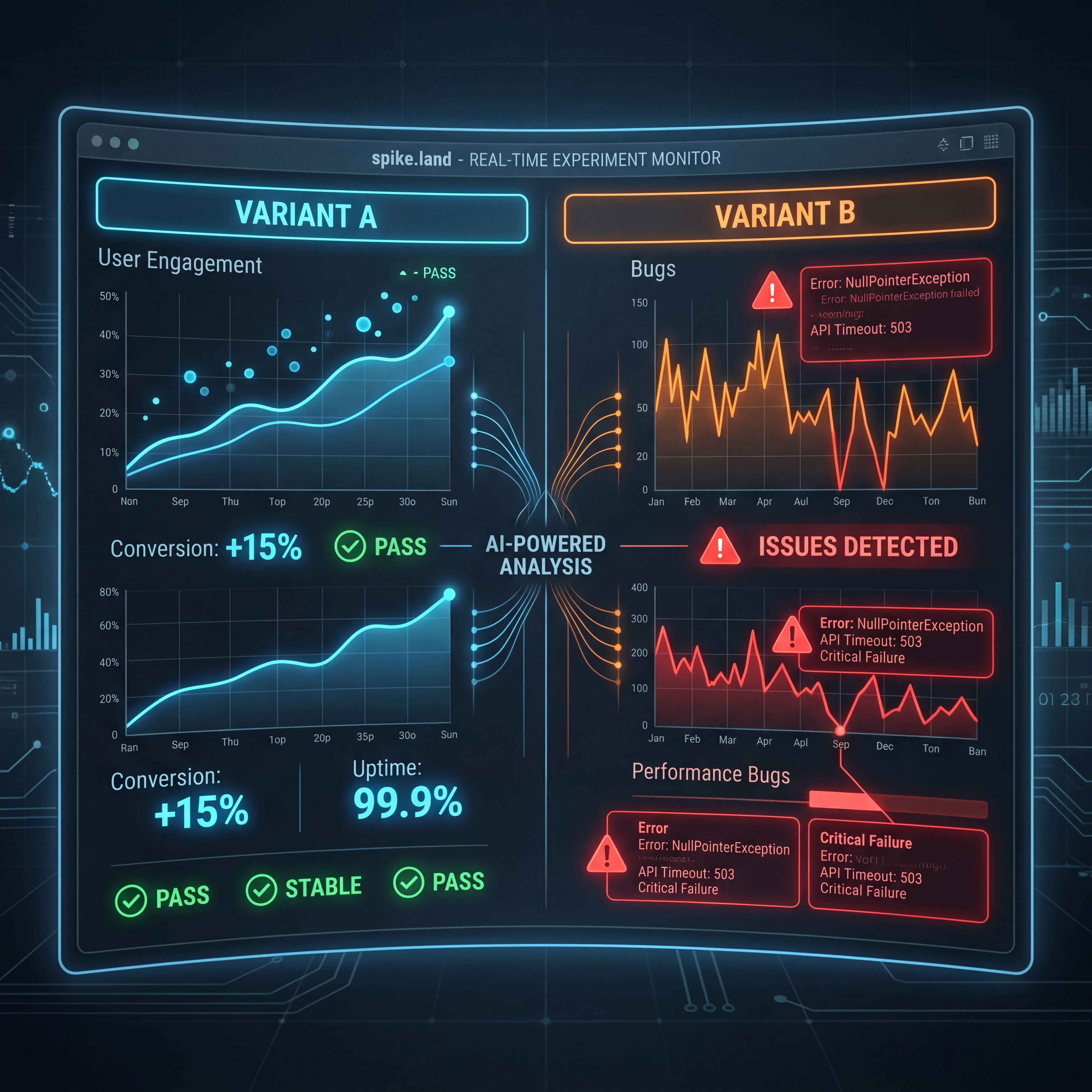
Bug Detection, Not Just Lift Detection
This is where the growth metric framing falls apart. Lift is a story. Error rate is a fact.
The quality angle shows up in two places.
First, error-heavy variants reveal themselves quickly. If one version produces meaningfully worse runtime behavior, you do not need to wait for a long product debate. The data is already telling you something.
Second, anomaly monitoring catches operational failures too. If an active variant suddenly has zero impressions, that is not a copywriting problem. That is a routing or rollout problem.
These are bug signals, not growth signals.
What This Means For An Open App Store
An open app store only works if quality can scale.
The more developers publish, the more chances there are for unstable behavior to reach users. The answer cannot be “manually inspect everything forever.”
So the platform needs a loop:
generate -> test -> observe -> promote -> learn
AI helps with generation and diagnosis. The experimentation system handles measurement and promotion. Together they make open publishing more realistic.
That is the real point of AI-powered A/B bug detection on spike.land. It is not a slogan. It is the platform learning how to ship safer apps at store scale.